There are over 6,500 languages spoken around the world , but mainly as a result of the growing dominance of English, it is estimated that by 2050, there will be only about 4,500 languages left, and only 3,000 in 2100.
Multilingual language models are large language models (LLMs) which, instead of being trained on text from only one language (usually English), are trained on text from dozens or hundreds of languages at once. Meta’s “No Language Left Behind” initiative trained a model on over 200 languages and Google has its “1,000 Languages Initiative”.
In New Zealand, the non-profit media organisation Te Hiku is using AI to help revitalise the Mori language (te reo). The ARC Centre of Excellence for the Dynamics of Language is also applying AI to preserve and grow languages of Australia’s First Peoples .
While demonstrations of the ‘power of good’ of generative AI models, a recent study by the US based Center for Democracy and Technology (CDT) cautions that, without guardrails, multilingual language models could “inadvertently further entrench the Anglocentrism they are intended to address.”
How LLMs work
It is important to note that “a large language model does not understand language: instead, it makes probabilistic inferences about text based on the distribution of language within the data it is trained on.” Accurate prediction by an AI is all about how much data it has to make the predictions from.
As the CDT study points out, computer-based language models are not new: what is new is their enormous size. Earlier generations of language models could only read text sequentially - i.e. solving the next word in a sentence. This meant two things: the language model struggled to understand the broader context of a sentence or document, which narrowed its ability to predict the next word; and there was a limit on the data on which the model could be trained, and hence its accuracy in predicting words.
LLMs broke this mould by processing data in parallel rather than in sequence, allowing the model to ingest so much data that it can learn associations between entire sequences of words, not just individual words. As the CDT report notes, “[w]ith enough data, a large language model may have such a rich and multifaceted representation of a language that it can learn to do new tasks with only a few, or even zero examples to fine-tune on.”
Why is there a risk that English will be the ‘mother tongue’ of AI?
English is the highest resourced language by multiple orders of magnitude: English accounts for 63.7% of websites, while only being spoken by only 16% of the world’s population. Given the insatiable appetite of LLMs, it is therefore easier to build LLMs in English. The only other languages which has enough ‘critical mass’ to support their own monolingual LLMs are Spanish, Chinese, and German (fun fact: Google’s French version of its LLM, BERT, is called CamemBERT).
The CDT report says that there could be an accelerating, self-perpetuating cycle, with English leaving even these other higher resourced languages in the dust:
More raw text data, also known as unlabeled data, means more data for the model to be trained on; more research means that there are more datasets annotated with information, also known as labeled data, that can be used to test how well models complete different types of language tasks. This creates a virtuous cycle for English-language NLP — more labeled and unlabeled data leads to more research attention, which leads to increased demand for labeled and unlabeled data, and so on.
It is not just a problem of limited or poorly applied vocabulary for LLMs operating in languages other than English. LLMs trained on a limited dataset have limited functionality: language models typically are unable to write code or add three digit numbers until they train on a certain amount of data, at which point their performance improves dramatically.
How LLMs can ‘bootstrap’ less resourced languages
The basic idea is to apply the extraordinary predictive power of LLMs across languages:
Multilingual language models are designed to address these gaps in data availability by inferring semantic and grammatical connections between higher- and lower-resource languages, allowing the former to bootstrap the latter.
The CDT report illustrates how LLMs can find correlations across multiple languages with the example illustrated below:
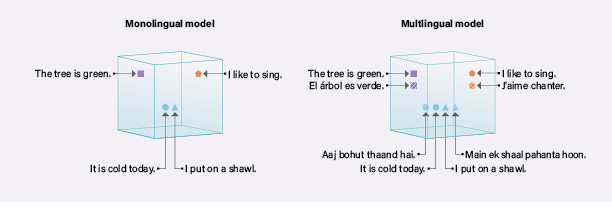
An Indian climate change researcher wants to use a language model to collect all Hindi-language tweets about the weather. A monolingual language model trained on just Hindi text may not have enough data to have seen the words “thaand” (“cold” in Hindi) and “shaal” or (“shawl” in Hindi) appear near one another in text, so it may miss that tweets to the effect of “Main Agast mein shaal pahanta hoon” (“I put a shawl on in August”) is a sentence about cold weather. A multilingual model, trained on data from English, Hindi, and many other languages may have seen text where “thaand” appears near “cold,” “shaal” appears near “shawl,” and “cold” appears near “shawl,” thereby allowing the model to infer that “thaand” and “shaal” are interrelated terms.
The risk that LLMs will be cultural assimilators
The problem is - going back to the overwhelming mass of English language data - that multilingual language models are still usually trained disproportionately on English language text. This then creates the obvious risk, as the CDT report points out, that the LLM ends up “transferring values and assumptions encoded in English into other language contexts where they may not belong.” Even BLOOM, a multilingual LLM part funded by the French Government designed to help ‘balance out’ the dominance of English language LLMs, is trained on data which is 30% in English.
It is not just the smaller data pool of non-English content available to train LLMs, but there are also quality issues with that data:
low resource languages tend to have data that comes from a less diverse set of sources, such as more formal sources such as law reports, parliamentary and government records, Wikipedia and, in many smaller languages, predominately the Bible. The full richness of the language - and especially idiom and every day speech - is not captured with enough data points.
somewhat ironically, the overwhelming success of translation programs, such as Google Translate, means that a lot of non-English language data scraped from the internet is machine translated from English in the first place. Also, a technique used by NLP programmers to ‘fill out’ non-English content can be to use machine translation to translate English content in the training data into the lesser resourced languages (and sometimes back again to cross check). Over-incorporation of machine translated language into the training data set can result in the problem of “translationese”: patterns of speech native speakers would not use, such as either oversimplifying or overcomplicating sentences, producing repeated words, using too common or too uncommon words, and borrowing too much or too little from the original (English) language.
while it is not altogether clear how multilingual language models work, one theory is that they have inferred language-agnostic concepts and universal rules that can be applied to any language. But sometimes languages are just so fundamentally different that this assumption does not hold true. For example, if a language without gender pronouns, such as Hungarian, is mapped onto a language with gendered third-person pronouns, such as English or even more so French, the LLM could force gender associations and biases of the gendered language onto the non-gendered one.
LLMs particularly struggle with less resourced languages in non-Latin script.
Testing and detecting problems in non-English renderings by LLMs can be difficult: “multilingual language models are particularly opaque because they make unintuitive, hard-to-trace connections between languages” (which, of course, is also their strength).
Recommendations
The CDT report recommends ‘guardrails’ for multilingual LLMs:
Companies that incorporate language models into their technical systems should always disclose how they are using them, which languages they are using them in, and what languages they have been trained on;
Because of the complexities of human speech and the error-prone nature of automated tools, decision-making systems built on top of large language models should be used within narrow remits and with adequate remedial channels for users encountering them. Those remedial channels and processes should have human reviewers with proficiency in the language in which that the AIsystem is deployed.
LLM developers need to involve not only language experts, but also civil society, local experts, heritage and language preservation advocates, linguists, and human rights experts. For example, India-based non-profit organizations have convened a range of gender, gender-based violence, communal violence, and other language experts to annotate training datasets in Indian English, Tamil, and Hindi to build a tool capable of parsing sentiment and toxicity on Twitter.
Responsibility lies not just with the LLM developers. Researchers and academics need to focus on creating self-sustaining scholarly NLP communities. The CDT report notes that Meta and Google have been assisting in this by sharing the code for training many of their multilingual language models and disclosing the data they train them on.
Interestingly, the CDT report warns that regulatory efforts to force social media companies to control misinformation could cause ‘collateral damage’ in the development of better multilingual LLMs:
Mandating the use of automated content moderation technologies or requiring companies to take down content in a limited time period (effectively requiring the use of automated technologies) opens the door for the overbroad removal of speech. Large language models, especially in non-English language contexts, are not a magical technology that can perfectly distinguish between good and bad speech. At best, they are an imprecise technology that fails to understand the context of speech — for instance, when an individual uses a slur versus when a journalist documents the use of a slur by that individual. At worst, they are tools that can be appropriated by governments to squash dissent and freedom of expression.
Read more: Lost in Translation: Large Language Models in Non-English Content Analysis

Peter Waters
Consultant